
Computer vision, player tracking and babysitting Claude Code
On sports analysis, 2D maps and letting go of the agent

There was a project that had been rattling around in my head for a while. The idea was to develop a model capable of taking amateur footage of futsal matches and producing a 2D representation of the game.
Amateur video is a hard case because it systematically violates every reasonable assumption you'd make about "clean" footage. The camera follows the play handheld, so the framing shifts constantly and a static field calibration doesn't cut it. The angle is low, which means players overlap each other and the field lines vanish in perspective. Artificial lighting creates glare and overexposed zones that make model calibration a nightmare. In low-quality video, a moving ball becomes an indistinguishable blob. And the frame inevitably catches people who shouldn't be there: touchline coaches, substitutes on the bench, spectators off the pitch.
The most mature models and datasets for sports tracking were built for 11-a-side football, shot from above in professional stadium setups. Futsal is essentially a data no-man's land.
A solid challenge, in other words. But what better opportunity to put the much-hyped Claude Code to the test?
Take #1: Futsal
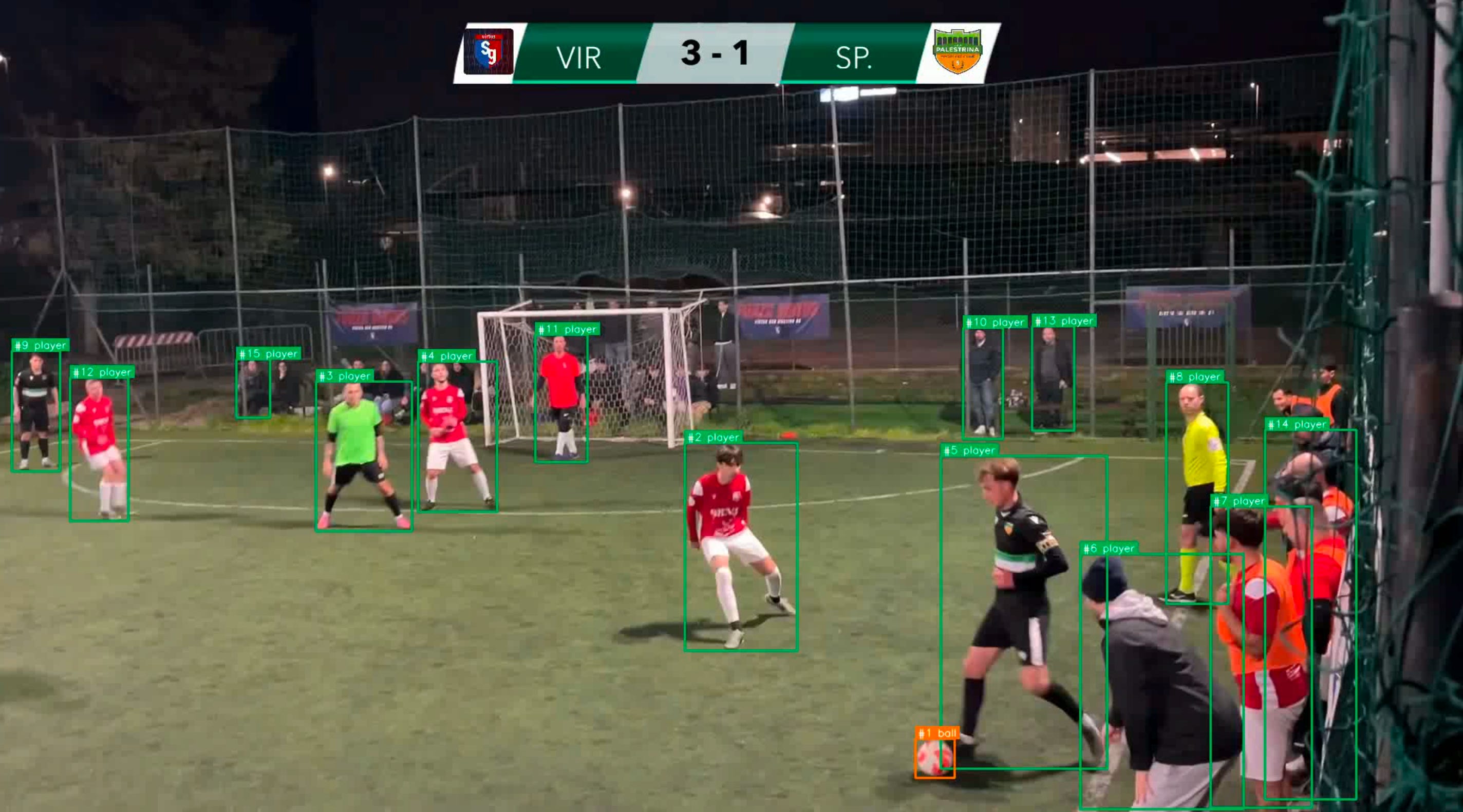
The first step was using YOLOv8n, an object detection model — a system trained to recognise and localise objects in an image — pre-trained on COCO, a generic dataset covering dozens of common object categories. The model analyses the video frame by frame and returns the position of everything it recognises. For players it works: across 460 frames it produces around 4,370 detections. For the ball it's a disaster: 14 detections total. The reason is simple: a moving futsal ball is small, blurred, and a model trained on generic internet images is not equipped to find it.
The next step was computing the homography matrix: a mathematical transformation that maps each pixel in the video to a real coordinate on the pitch. In practice, it's what lets you say "this pixel corresponds to that point on the field" and therefore project player positions onto the 2D map. The automatic approach, consisting in isolating the white field lines via colour filtering (HSV masking), finding the lines with a classic computer vision algorithm (HoughLinesP), and estimating the transformation with RANSAC, produced zero valid results across 83 sampled frames. Artificial lighting and the low quality of the available footage made the lines unreadable to the filter parameters. The fix was manual annotation: I built an interactive tool where you click the corresponding points between the 2D field template and a frame extracted from the video.
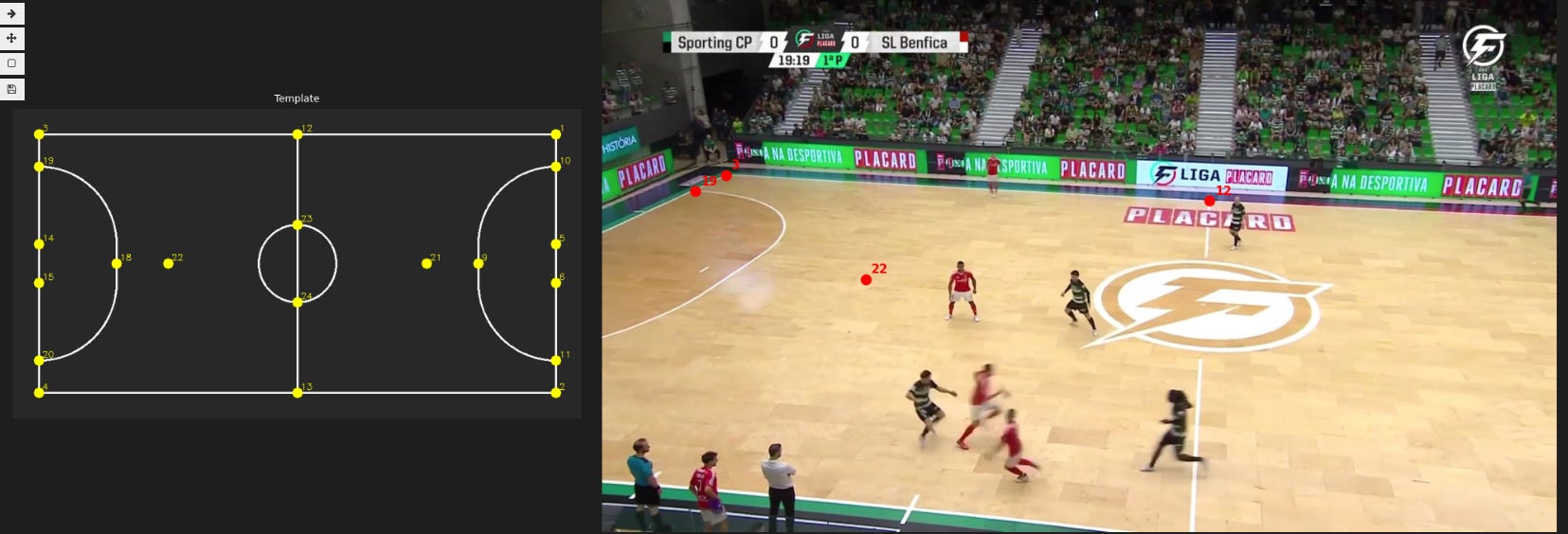
I annotated 28 key frames, then propagated the calibration to the remaining frames by tracking visual features between consecutive frames (ORB feature tracking).
There was an additional problem: the camera moves constantly following the play, so a single static matrix isn't enough. In other words, the scattered dots had to be connected frame by frame into continuous trajectories: a player in motion needs to maintain the same identity over time, not become a new object with every frame. This is where a tracker comes in, in this case OC-SORT: an algorithm that combines the current position of detections with a movement prediction to keep IDs consistent over time. The result: 70 distinct IDs for roughly 10-12 real players. The tracker kept losing the thread due to occlusions and the rapid movements typical of futsal (at least when I'm not the one playing).
To collapse those 70 fragments into stable identities I used OSNet, a model specialised in re-identification, i.e. recognising the same person across different moments and angles based on visual appearance. The model produces for each track fragment a numerical vector (embedding) describing the player's appearance. These vectors are then compared to determine which fragments belong to the same person, using shirt colour as an additional grouping criterion. The result: from 54 valid fragments down to 3 identities. A 94% reduction that's too aggressive, since many real players end up merged into a single ID because the shirts look alike and the fragments are too short to distinguish them reliably.
The final minimap was supposed to run alongside the original clip, but producing it meant solving a whole series of problems: people outside the pitch being projected inside due to homography errors, a flickering ball from intermittent detections, and a hard dependency on manual annotation of key field points.
At some point I had to admit that the problem wasn't solvable in the short term with the tools I had, and that even with better footage the situation wouldn't have improved significantly. It would have required annotated data that doesn't exist, models nobody has trained on that domain, and above all the patience I lost years ago.
Take #2: Tennis
I decided to change direction and try tennis, a more controlled domain, with stable footage, where I could at least verify the rest of the pipeline.
For player detection I used YOLOv8n again, which delivered encouraging results: 20580 detections versus the 4370 from futsal.
For the ball I ditched YOLO entirely. A tennis ball has characteristics (yellow, small, always moving) that lend themselves to a more direct approach: compute the difference between consecutive frames to isolate moving pixels, filter by colour with an HSV mask on the yellow-green range, discard shapes that don't look like a ball (too large, too elongated, not round enough), and exclude candidates that fall inside the player silhouettes (did Alcaraz really have to wear lemon yellow shorts?). No neural network, and the ball detected in 819 frames out of 1341, versus 14 in futsal.
Field registration was the clearest confirmation that the previous problem was a domain problem, not a method problem. The court is fixed, the white lines are high-contrast, the lighting is stable. These conditions made annotation much faster and more precise. The method was the same as in futsal, consisting in manual selection of key field points, except this time it worked on the first try, with no camera pan to manage and no need to propagate calibration frame by frame.

OC-SORT tracking produced 54 IDs as in futsal, but collapsing them into stable identities was far simpler this time: with only 2 players on court, all it took was filtering out tracks that were too short or too static, then clustering by shirt colour with K-means and k=2, with no need for OSNet.
The ball kept appearing and disappearing between frames, making the trajectory unusable. Searching for a solution I came across the Kalman filter: an algorithm that combines observed detections with a predictive movement model to estimate position even in frames where the ball isn't detected, filling gaps of up to 15 consecutive frames and producing a continuous trajectory.
The final result, while clearly better than futsal, came with several issues. The ball flickers annoyingly every time it slows down or bounces, because without movement there's no signal and detection simply disappears. Player detection drops without warning in certain areas of the court, making trajectories patchy and unreliable. And the attempt to plot the ball trajectory in 2D turned out to be essentially pointless: a tennis ball travels in three dimensions, bounces, rises off the ground, so the homography, which by definition assumes everything lies on the same plane, produces distortions large enough to make the projection meaningless. A problem that never even arose in futsal, and that in tennis is absolutely central.
Babysitting Claude Code
The starting point was the paper SoccerNet Game State Reconstruction: End-to-End Athlete Tracking and Identification on a Minimap* di Somers et al., a work that formalises exactly the problem I was trying to tackle, building a complete pipeline to reconstruct player positions and identities on a minimap from broadcast footage of 11-a-side football.
The project intimidated me, but it turned out to be the right opportunity to experiment with the much-discussed Agentic AI. My approach was to personally choose the architecture, the tools, and the clips to run the models on. I also described problems as they emerged (for example the cluttered minimap, the broken field homography, the ball disappearing and reappearing) and manually annotated the field keypoints in the video frames. I delegated the code writing, parameter choices and debugging to Claude Code.
The experience? Frustrating, as it always is when you deal with artificial intelligence for more than 5 minutes. Now it's called Agentic AI, because it can plan, "reason", and iteratively evaluate results, but underneath it's the same models as before. The same models that can't count how many letter "A"s are in a word, but to which we blindly entrust our lives (and sadly, it seems, the lives of others too). The same models as before, but chained together in sequence so as to relieve us of the burden of even evaluating the direction they're heading, making us even less aware of what's happening behind the scenes. When something goes wrong, you have to hope the agent can fix the problem on its own, because at that point you're already offside (to stay on theme): within seconds the codebase becomes a labyrinth stuffed with unsolicited garbage, impossible to understand or debug, and so you have no choice but to trust the model even more, until everything becomes incomprehensible and you have to start over.
But this is the direction the world has taken, and the individual can't resist, because you risk falling behind (and on top of that, being written off as a dinosaur, a bore, a pedant). You can't stop, because you always have to do more.
Tutto, malissimo e subito.